

⚽️ 목표
기존 CI의 실행 시간과 요금 다이어트
•
첫 배포 때 GitHub actions에 CI 코드를 작성 후 많은 신경을 쓰지못한 CI는 DX를 현저하게 떨어뜨리고 있었다.(문제점은 후에 기술) e2e 테스트 코드는 아주 긴 시간이 걸렸으며, e2e의 경우 실패했던 이유를 CI 실패 과정에 출력되는 에러를 확인하며 유추할 수 밖에 없는 상황이였다.
•
필자가 속한 팀 뿐 아니라 많은 팀에서 마주치는 문제라 생각한다. 기능추가에 쫓기다보면 CI와 같은 개발 이외의 면에는 신경을 덜쓰게 되며 묵히고 묵힌 코드(기술부채)로 남겨지기 마련이다. 개발자가 아닌 다른 사람이 보기에 눈에 보이는 프로덕트 기술 추가가 아니면 대부분 “개발팀 쟤넨 뭐해?”라는 상황에 마주치기 마련이다.
•
코드스페이스 상에서의 기술 부채 뿐 아니라 DX 영향을 끼칠 수 있는 기술부채도 매우 중요한 기술 부채다. - 뭐가 될 수 있을까? 모노레포 상 캐시 종속성 관리, CI/CD 속도 개선, pre commit 속도, 방식 개선과 같은 개선 사항들은 개발자의 퍼포먼스에 엄청난 영향을 끼친다. 개발자라면 모두가 알고 있는 사실이지만 개발에 대한 이해도가 떨어지는 조직에선 이걸 설명해야하는 것 또한 하나의 업무가 될 수 있다. 결정권자와 편하게 대화를 시작해보자. 너무 무겁게 대화를 시작해야할 경우 개발을 알려줘야하는 상황 까지 올수가 있으니…
글에서 다루는 키워드
•
Github actions - cache, matrix, large runner
•
Playwright - sharding, worker
•
BuildJet(GitHub actions runner 제공 서비스)
글에서 다루지 않는것
•
이 글은 Github actions와 Playwright의 기본적인 사용법을 다루지 않는다. 각 기술의 사용법은 공식문서에서 확인하는걸 추천한다.

◦
코드는 공식문서와 함께라면 쉽게 작성할 수 있다 생각하므로 이 글에는 기본적인 사용법 뿐 아니라 실제 GitHub actions 코드도 많이 등장하지 않는다. (YAML 찐짜 씷어요 찐짜 쪠빨 끄만쓰꼐 햬쭈쎼요)
 TL;DR
TL;DR
•
Flaky한 E2E 테스트는 “통과 됐다 안됐다 하는 일정치 않은 결과물을 보여주는 테스트”를 뜻한다.
•
Flaky 하지않은 E2E 테스트는 없다. 주기적으로 관리 해줘야한다. → 미루지마라 미루는 순간 팀의 E2E CI의 신뢰성은 떨어지며 누구도 관리하지 않는 의미없이 돈만쓰는 CI가 되어버릴 가능성이 높다.
•
GitHub actions의 기본 runner는 많이 느리다.
•
Github actions large runner가 할당되는데는 시간이 걸리며 싱글코어 성능도 좀더 좋다.
1. 기존 workflows 파악
graph TD subgraph jobA[종속성 설치 job] A-1[pnpm 종속성 설치] -.-> A-2[Playwright 브라우저 설치] -.-> A-3[(GitHub 캐시에 저장)] end subgraph jobB-1[admin e2e job] B-1[(캐시 복구)] -.-> B-2[e2e 테스트 실행] end subgraph jobB-2[메인 서비스 e2e-1 job] C-1[(캐시 복구)] -.-> C-2[e2e 테스트 실행 - 1/3] end subgraph jobB-3[메인 서비스 e2e-2 job] D-1[(캐시 복구)] -.-> D-2[e2e 테스트 실행 - 2/3] end subgraph jobB-4[메인 서비스 e2e-3 job] E-1[(캐시 복구)] -.-> E-2[e2e 테스트 실행 - 3/3] end subgraph jobB-5[unit test job] F-1[(캐시 복구)] -.-> F-2[unit 테스트 실행] end jobA --> jobB-1 --> 완료 jobA --> jobB-2 --> 완료 jobA --> jobB-3 --> 완료 jobA --> jobB-4 --> 완료 jobA --> jobB-5 --> 완료 완료
Mermaid
복사
•
종속성 설치 job은 각종 테스트에 필요한 파일들을 설치후 cache에 저장하는 일련의 과정을 가지고 있는 job이다.
•
메인 서비스 e2e job은 느린 테스트 속도 개선을 위해 매트릭스를 이용하여 여러개의 job을 생성 후 Playwright의 sharding을 이용해 테스트를 나눴다.
캐싱을 이용한 종속성 및 브라우저 실행파일 공유
•
하위 job인 admin e2e, 메인 서비스 e2e(1,2,3), unit에서 각각 따로 설치하지 않고 종속성 설치 job에서 한번에 설치후 공식 action 중 하나인 cache 를 이용하여 캐시에 보관 후 하위 job들은 종속성 설치 job에서 미리 설치한 pnpm 종속성과 브라우저 캐시를 불러와 각종 작업을 수행한다.
2. 기존 actions 문제점 파악
unit test의 불필요한 기다림
•
unit test에는 playwright 브라우저가 필요없음에도 불구하고 playwright 브라우저가 설치될 때 까지 대기한다.
push 때 마다 계속 수행된 캐시 불러오기
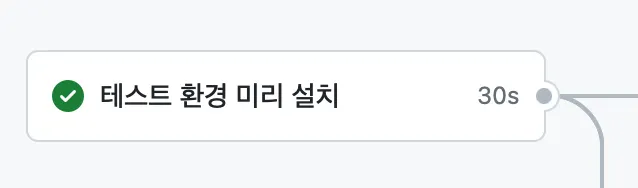
PR Open 후 push 때마다 캐싱을 다시 가져오는 시간
•
Workflow 첫 실행 시(PR이 open 됐을 때) 캐싱을 이용하여 pnpm 종속성 및 playwright 테스트용 브라우저를 설치 후 캐시에 저장하는 역할을 하는 job이다.
•
PR open후 변경 사항을 적용하고 열린 PR에 push를 할 경우 위 사진에서와 같이 30초가 소요된다. 저장된 캐시에서 각종 파일들 복구에 걸리는 시간, job 초기화(checkout action으로 코드 가져오는데 걸리는 시간), 각종 cleanup에 필요한 시간이기 때문이다.
e2e 테스트 결과 확인의 부재
•
e2e 테스트에서 테스트 케이스가 실패하는 결과(report)가 업로드 되고있지 않았다. 이로인해 테스트 케이스 실패에 정확한 이유를 알 수 없었고 개발자는 실패 이유를 유추할 수 밖에 없는 상황이다.
오래걸리는 e2e 테스트 - 느린 GitHub actions
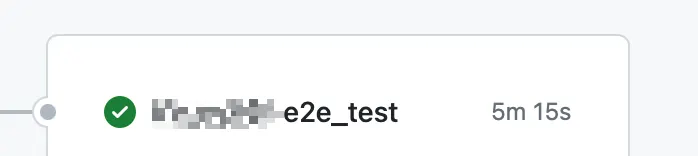
메인 서비스의 e2e 테스트 소요 시간
•
기본적으로 브라우저를 기반으로하는 e2e 테스트에는 많은 리소스가 필요하며 시간이 오래걸린다.
•
다른 테스트의 경우 대부분 3분 이내에 끝나는 반면 서비스1의 테스트는 빠를 경우 5분, 느릴경우 6분 후반대 까지 가는 경우가 있는 상황이었다.
•
이 단점은 GitHub actions의 Matrix와 Playwright의 sharding을 이용해 이미 부분적 개선된 상황이다. 자세한 내용은 2-1. Matrix와 sharding에서 후술한다.
개선해야할 사항
•
결과적으로 개선해야할 사항은 4가지다.
◦
unit 테스트의 불필요한 기다림
◦
push 때 마다 계속 수행되는 캐시 불러오기
◦
e2e 테스트 결과 확인의 부재
◦
오래걸리는 e2e 테스트 - 느린 GitHub actions
•
이후 글에선 위 문제사항들의 개선 및 이로인한 긍정적인 side effects 및 대안을 확인한다.
2-1. matrix와 sharding
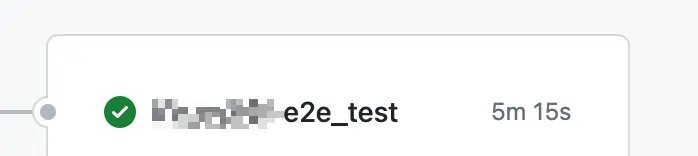
Sharding을 사용하지 않는 메인 서비스의 e2e 테스트 기간
•
기존 메인서비스 e2e의 경우 CI에서는 5분에서 늦을 경우 6분까지 걸리는 상황이였다.
•
기존 느린 2코어 runner에서는 당연하게도 Playwright의 mutiworker를 사용할 경우 오히려 테스트 코드 실행이 더 느려졌으며 그나마 느린 속도로 돌아가는 테스트코드의 실패율은 더 높아졌다.
•
GitHub actions에 Large runner가 정식으로 추가되기 이전에는 테스트 시간을 줄일 수 있는 최선의 방법이였다.
sharding
•
여러개의 머신에서 테스트를 나눠서 실행할 수 있도록 도와주는 Playwright의 기능이며 쉽게 활성화 할수 있다.
# 머신 1
npx playwright test --shard=1/4 # 전체 테스트 중 quarter(1/4)에 첫번째 quarter만 실행
# 머신 2
npx playwright test --shard=2/4 # 전체 테스트 중 quarter(1/4)에 두번째 quarter만 실행
# 머신 3
npx playwright test --shard=3/4 # 전체 테스트 중 quarter(1/4)에 세번째 quarter만 실행
# 머신 4
npx playwright test --shard=4/4 # 전체 테스트 중 quarter(1/4)에 네번째 quarter만 실행
Bash
복사
Sharding example
•
기본적으로 테스트를 실행하는 머신의 성능이 좋을 경우 playwright의 worker를 이용하면 된다. 하지만 GitHub actions의 기본 runner는 성능이 매우 낮으므로 worker의 사용이 오히려 테스트의 flaky함을 증가시키고 전체적인 시간도 더 걸린다.
•
12개의 테스트를 4개의 머신에서 sharding을 이용할 경우 각 머신에서 테스트를 3개씩 나눠 실행하므로 전체적으로 실행되는 코드실행 시간이 줄어든다.
sharding을 어떻게 실행 시킬 것 인가
•
4개의 커맨드를 각 job에서 어떻게 실행시킬까? job 4개를 직접 만들어서 만들 것인가?
e2e_test-1:
needs: installing_environment
timeout-minutes: 10
runs-on: ubuntu-latest
# 생략
e2e_test-2:
needs: installing_environment
timeout-minutes: 10
runs-on: ubuntu-latest
# 생략
e2e_test-3:
needs: installing_environment
timeout-minutes: 10
runs-on: ubuntu-latest
# 생략
e2e_test-4:
needs: installing_environment
timeout-minutes: 10
runs-on: ubuntu-latest
# 생략
YAML
복사
반복이 많이되는 actions yaml
•
이런 반복되는 job 생성 코드를 위해 matrix가 존재한다.
matrix

•
matrix는 특별한 로직이라기 보다는 “반복되는 여러 job들을 하나의 job에서 배열(또는 고차원 배열)로 만들어 편하게 다수의 job을 생성하는 기능”이라고 보면 편하다.
개선
# 생략
e2e_test:
needs: installing_environment
timeout-minutes: 10
strategy:
fail-fast: true
matrix:
shard: [1, 2, 3]
name: e2e-${{matrix.shard}}
# 생략
YAML
복사
•
Matrix를 사용할 경우 큰 변화 없이 반복되는 job의 경우 쉽게 코드를 단순화 할 수 있다.
•
Matrix를 사용할 경우 여러 job을 명시적으로 생성할 필요없이 e2e-1, e2e-2, e2e-3 job들이 runtime에 자동으로 생성된다.
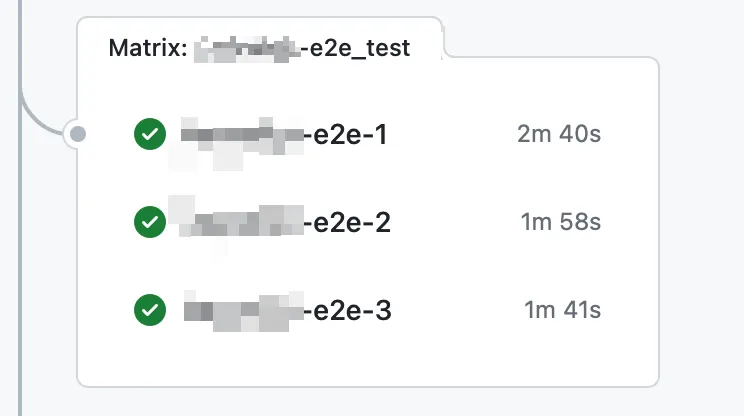
matrix로 개선한 메인서비스 e2e test job
3. unit test의 불필요한 기다림
•
기존 종속성 설치 job은 두개의 job에서 직렬로 실행되어 unit test는 playwright 브라우저가 필요 없음에도 불구하고 작업을 대기하고 있는 상황이였다.
graph TD subgraph jobA[종속성 설치 job] A-1[pnpm 종속성 설치] --> A-2[Playwright 브라우저 설치] --> A-3[(GitHub 캐시에 저장)] end jobA -.생략.-> 완료 jobA -.생략.-> 완료 jobA -.생략.-> 완료 jobA -.생략.-> 완료 jobA -.생략.-> 완료
Mermaid
복사
기존 종속성 설치 job
개선
graph TD subgraph jobA[종속성 설치 job B] A-1[pnpm 종속성 설치] --> A-2[(GitHub 캐시에 저장)] end subgraph jobB[종속성 설치 job A] B-1[Playwright 브라우저 설치] --> B-2[(GitHub 캐시에 저장)] end jobC-1[admin e2e job] jobC-2[메인 서비스 e2e-1 job] jobC-3[메인 서비스 e2e-2 job] jobC-4[메인 서비스 e2e-3 job] jobC-5[unit test job] jobA -..-> 대기 jobB -..-> 대기 jobA --대기 없이 바로실행--> jobC-5 대기 --> jobC-1 --> 완료 대기 ---> jobC-2 --> 완료 대기 ---> jobC-3 --> 완료 대기 ---> jobC-4 --> 완료 jobC-5 --> 완료
Mermaid
복사
기존 종속성 설치 job
•
종속성 설치 job을 A,B 두개로 나눈 후 pnpm 종속성만 설치하는 job B의 경우 바로 unit test job을 실행하게 Github actions 코드를 변경했다.
4. push 때 마다 계속 수행되는 캐시 불러오기
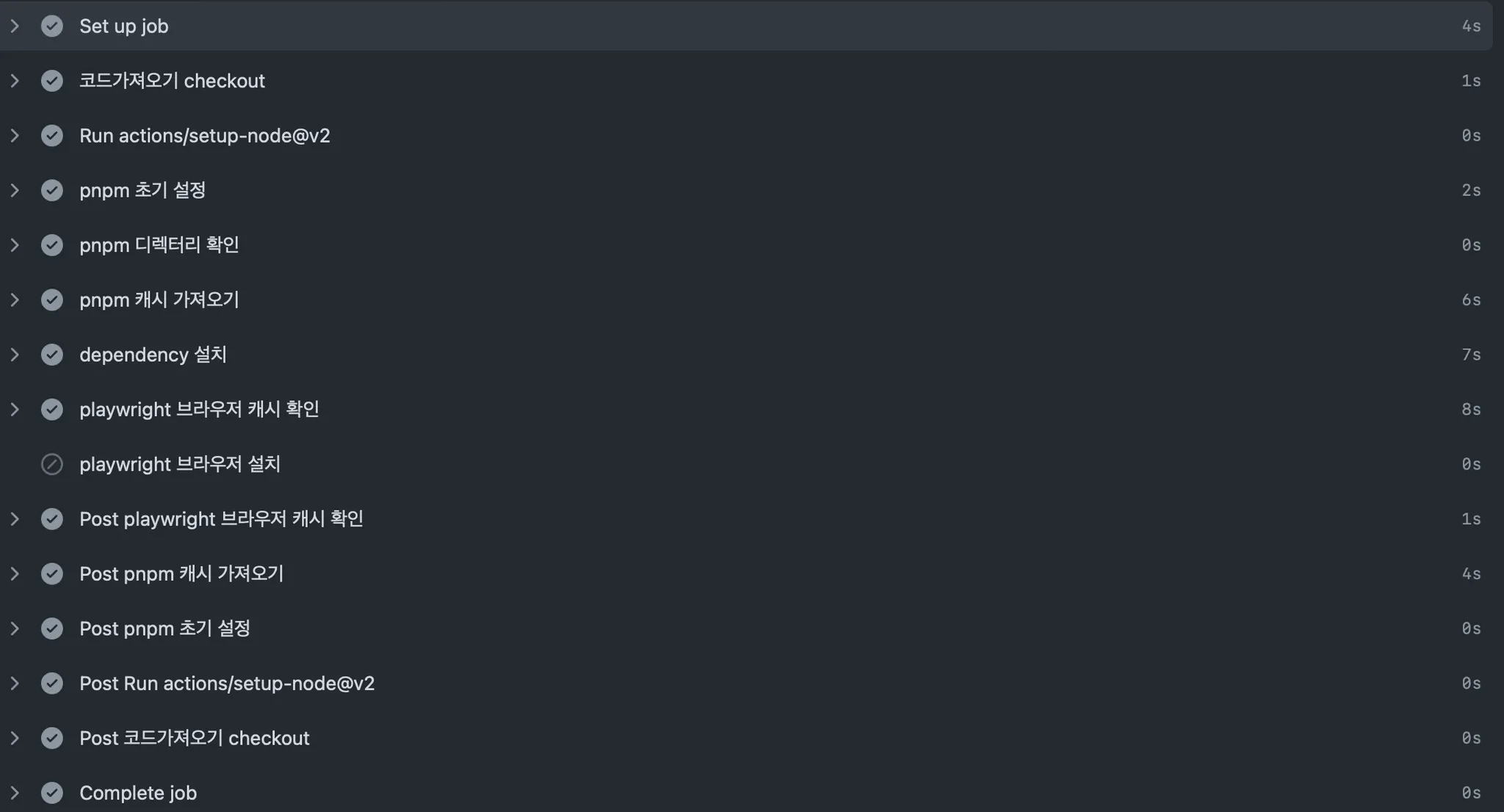
무의미하게 낭비되는 시간 + 요금
•
PR이 한번에 approve 되고 머지되는 희망적인 결과가 항상 도출되면 좋지만 적어도 나의 경험으로는 PR이 한번에 approve 되는 일은 아주 흔치않은 케이스였다. 개발자도 인간이기에 발생할 수 밖에 없는 코드상 문제점이 존재하고 팀원들의 코멘트를 확인하다보면 많게는 PR open 후 4회 5회 이상 코드가 수정된다. 기존에 존재하던 job의 프로세스는 아래와 같다.
◦
job setting
◦
checkout
◦
pnpm 종속성 cache 가져오기(이미 존재함에도 불구하고)
◦
playwright 종속성 cache 가져오기(이미 존재함에도 불구하고)
◦
모든 clean up 작업
개선
•
위의 프로세스는 불필요한 작업임에도 불구하고 30-40초 정도 걸렸으며 첫 1회 PR Open 시 실행 후 다시 실행될 필요가 없는 로직이다. 종속성 설치 job의 설정 부분에 if 분기문을 추가하여 pull_request가 openend일 때만 실행하는 로직을 추가할 경우 해당 job은 PR 첫 open 후 그 후엔 실행되지 않는다.
jobs:
# 종속성 설치 job
installing_environment:
name: 테스트 환경 미리 설치
timeout-minutes: 30
runs-on: ubuntu-latest
# 추가된 라인
if: github.event_name == 'pull_request' && github.event.action == 'opened'
steps:
- uses: actions/checkout@v3
name: 코드가져오기 checkout
# 생략
YAML
복사
종속성 설치 job에 추가된 if 조건문
•
이 후 실행되는 admin e2e job, 메인 서비스 e2e job(1,2,3), unit test job에도 if 분기문을 추가하여 이전 job이 skip되더라도 실행되게 만들어야한다.
# 메인 서비스 e2e job
e2e_test:yaml
needs: installing_environment
timeout-minutes: 10
# 추가된 라인
if: always()
YAML
복사
종속성 설치 job 실행 후 실행되는 job들에 추가된 if 조건문
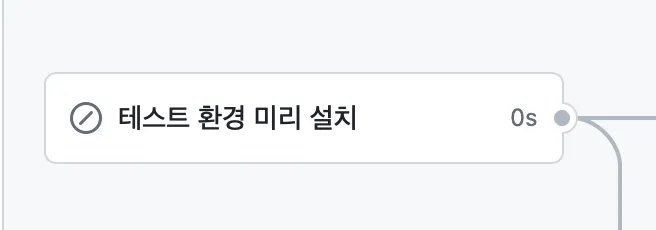
더 이상 실행되지 않는 종속성 설치 job
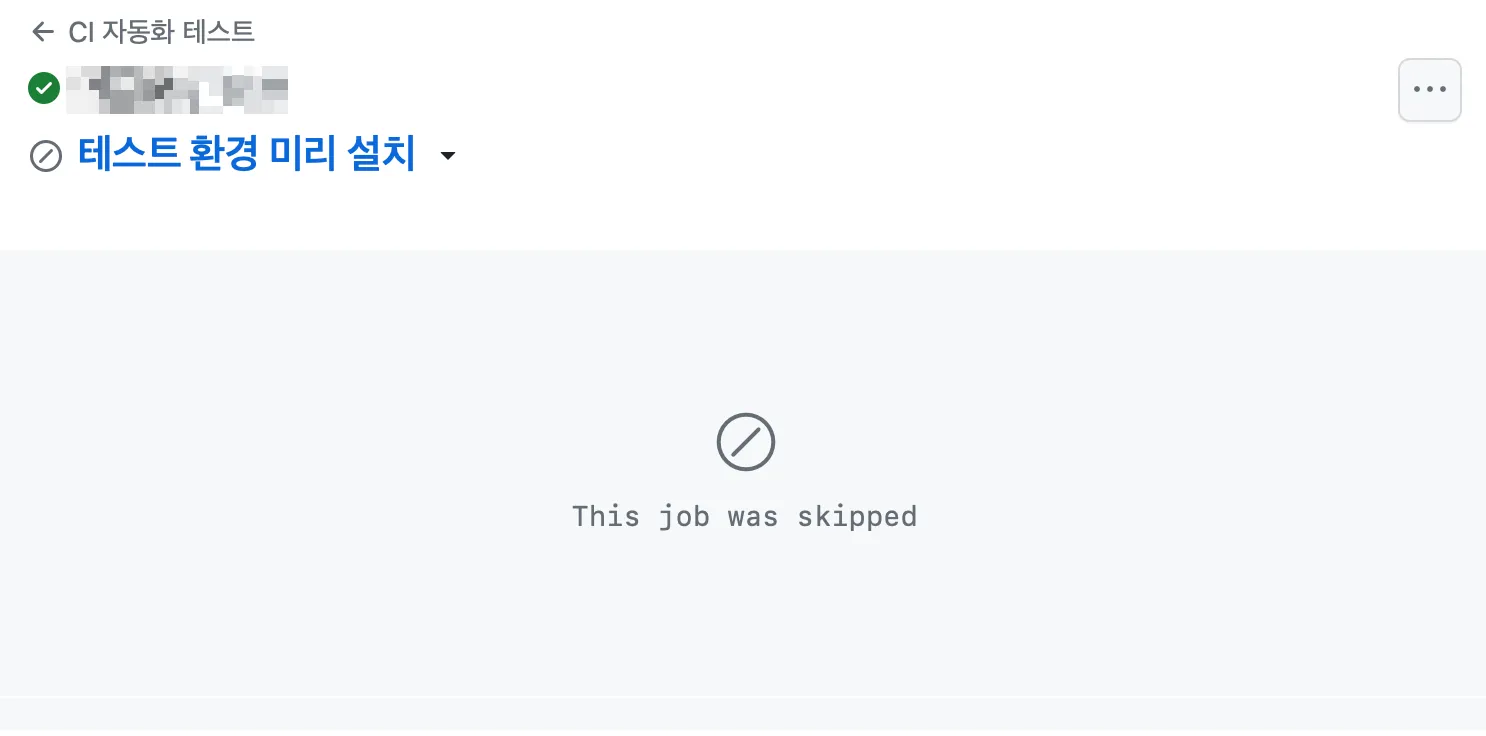
skip된 job
•
코드 수정 후 ci를 다시 실행하면 이와같이 해당 job이 첫 opend에만 실행되고 skip 된다.
•
결과 → Open된 PR에 재 push 시 30초가 줄어든다.
5. e2e 테스트 결과 확인의 부재
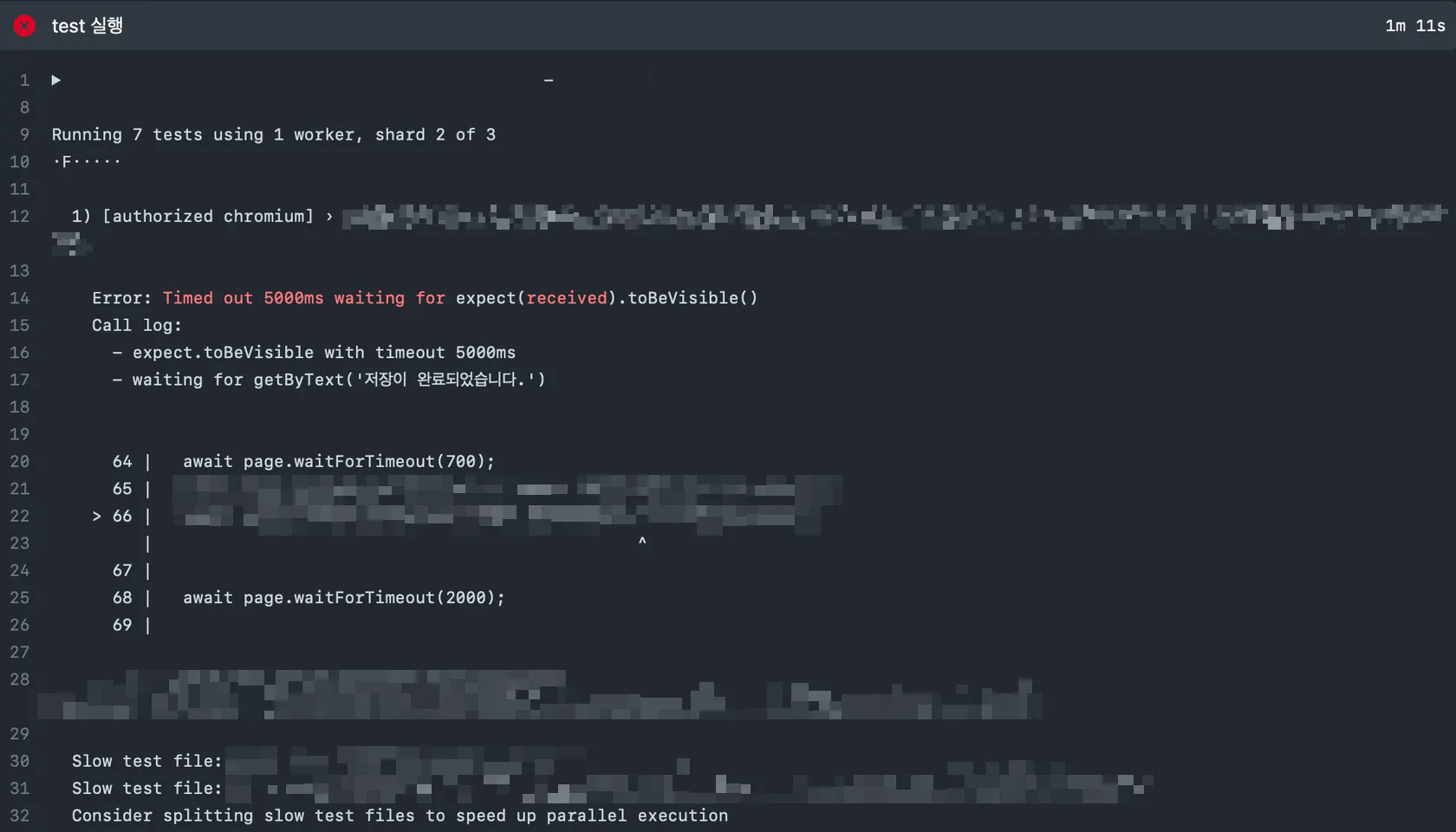
GitHub action에서 확인할 수 있는 불분명한 테스트 실패 이유
•
실패 이유를 유추할 수 밖에 없다? → 위의 오류 메시지만 확인했을때는 “저장이 완료되었습니다.”라는 토스트 메시지가 출력되지 않았다. 라는 정보만 제공된다. 실제 e2e는 컴포넌트 테스트, 유닛 테스트와는 다르게 실제 headless 브라우저에서 실행되므로 더 복잡한 이유가 존재한다.
•
해당 테스트의 경우 실제 실패이유를 Plawright report를 이용해 확인해본 결과 “렌더 당시 정의되지 않은 값 참조로 인한 error overlay가 출력되어 실패”가 확인 됐다.
•
e2e의 경우 실패에 대한 report 확인은 선택이 아닌 필수다. unit, component와 같이 간단한 로직 검사가아닌 전체적인 웹 프로덕트를 화면에서 테스트하기 때문에 테스트 실패의 이유가 훨씬 더 많으며 복잡하다. → 거기에 로컬 개발 머신과 github actions runner 성능 차이가 크게 날 경우 실패의 이유, 테스트 실패의 possible reasons는 더욱 다양해진다.
개선 방안
export default defineConfig({
reporter: [["html", { outputFolder: "playwright-report" }]],
retries: 0,
use: {
trace: "retain-on-failure",
},
// 생략
TypeScript
복사
playwright.config.ts에 추가한 설정값
•
playwright.config.ts에 테스트 코드에 대한 report를 생성하는 설정을 추가
◦
테스트코드 실패 시 재시도는 비활성화 했다. 한번 실패한 테스트코드는 또 실패할 가능성이 높으므로 재시도할 필요성이 없다.
◦
만약 재시도 시 성공 한다하더라도 같은 문제가 발생할 가능성이 높으므로 테스트 코드를 수정해야한다. → 재시도로 인한 테스트 소요시간 증가 또한 문제 중 하나다.
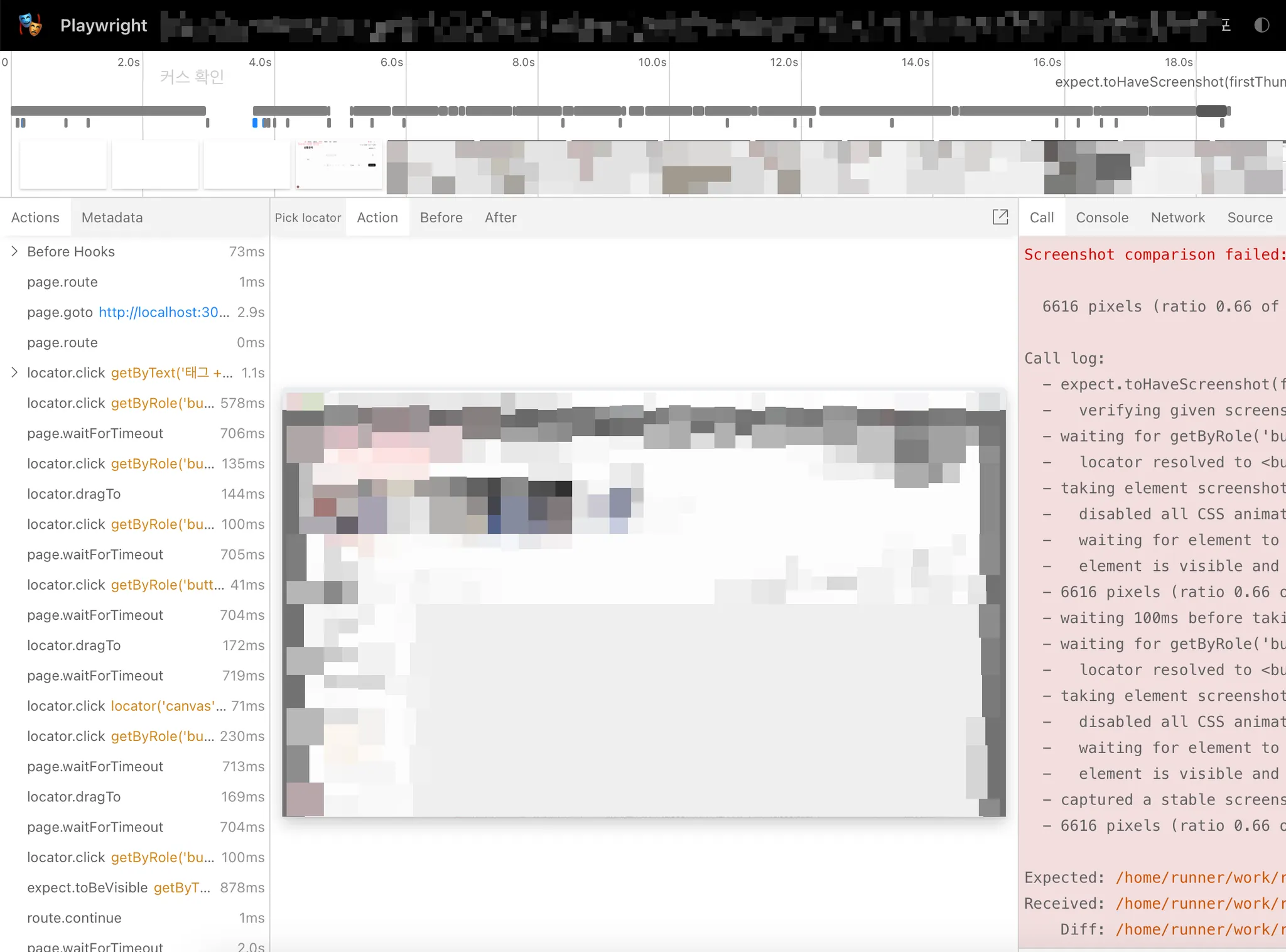
trace 예시 화면
◦
실패한 테스트 코드의 trace 결과물은 위와 같다. 상세하게 시간에 따라 변화된 화면까지 모드 트레이싱한다. 터미널에만 출력되는 결과로는 정확한 테스트 실패의 결과물 파악이 불가능하다. 실패 report의 상세한 결과가 없을 경우 터미널에 출력된 실패한 테스트의 결과는 유추할 뿐 이다.
◦
retain-on-failure 옵션을 추가해 실패한 테스트의 경우에만 trace를 저장한다.
- name: test 결과 업로드
if: always()
uses: actions/upload-artifact@v3
with:
name: # 리포트 파일 명
path: # 리포트 파일이 존재하는 위치
YAML
복사
Artifects에 업로드된 Playwright 리포트
•
uplaod-artifect actions를 이용해 리포트(trace)를 upload 할 수 있으며 actions summary에서 다운로드하여 확인할 수 있다.
6. 오래걸리는 e2e 테스트 - 느린 GitHub actions
GitHub action은 느리다
•
buildjet 서비스에서 작성한 GitHub actions에 대한 퍼포먼스 벤치마크 글 이다. 결국 “우리 프로덕트 쓰세요”인 글이니 적당히 걸러듣는다 쳐도 GitHub actions가 얼마나 느린지 알기에는 좋은 글이다. 항상 “왜 내가짠 e2e는 GitHub actions에만 들어가면 실패하는 걸까?”에 대한 좋은 답이 될 수 있다.
◦
아마도, 높은 확률로, 이글을 읽는 당신(개발자)의 단말기는 아주 좋은 성능을 가진 단말기 일 것 이다. 필자의 경우 MacBook Pro 14인치(M2 pro, 32GB)이다.
◦
위의 벤치마크 글에 따르면 2015년에 출시된 맥북과 비슷하거나 느린 성능을 가진 GitHub actions runner은 당연하게도 비교가 안되게 느리다. → 작성한 e2e 테스트코드는 당연하게도 느리게 돌아가고 각종 컴포넌트의 렌더링, 네트워크 속도마저도 느리다.
◦
로컬 개발환경(최고의 환경)에서는 문제없이 작동 되지만 비교적 아주 느린 GitHub actions runner 에서는 로컬 개발환경에서 문제없던 코드들이 문제가 생길 수 밖에 없다.
▪
느린 렌더링 → 이전에 설정한 waiting 시간보다 요소 렌더링에 훨씬더 오래 걸릴 수 있다.

•
GitHub actions에 사용되는 기본 linux runner의 사양은 2코어 CPU, 7GB 램, 14GB SSD 용량을 가지고 있다. e2e 테스트 코드가 돌아가는것 조차 버거운 사양이다.
◦
필자의 직장동료중 하나는 m1 8GB램 맥북에어에서 e2e 테스트 코드를 돌리던 도중 항상 개발 서버가 꺼지는(또는 테스트가 중간에 사망) 상황 까지 존재했다. 8GB 램조차 버거운 상황임에도 불구하고 GitHub actions 기본 runner에서는 돌아가는 이유는 GUI + 백그라운드에서 돌아가는 여러 프로그램들이 메모리에 상주하고 있지 않기 때문이다.
playwright workers
•
기본적으로 playwright는 50% worker 설정을 가지고 있다. → logical core의 2분에 1만 활용하는 설정. 자신의 테스트가 가지고있는 코어의 50%이상 설정될 경우 오히려 e2e 테스트가 오래 걸리고 Flaky 해진다.
6-1. large runners
About larger runners - GitHub Docs
GitHub offers runners with more RAM, CPU, and disk space.

https://docs.github.com/en/actions/using-github-hosted-runners/about-larger-runners#machine-sizes-for-larger-runners
GitHub actions에 추가된 larger runners 종류
•
Github도 이런 문제점을 파악하고 larger runner를 도입했다. 정확히 말하자면 성능만 추가하는게 아닌 그룹화, public IP 발급과 같은 추가적인 기능까지 가지고 있다. → GitHub 팀 이상에서만 사용 가능한 기능

•
runner 별로 요금의 차이가 존재하며 코어 수에 비례하게 요금이 증가된다(4코어 runner는 2코어 runner의 요금에 2배가 된다.)
•
2배의 요금이 들어간다고 2배의 시간을 줄일 수 있다는 자세로 접근해서는 안된다. → 적절한 선택 챕터에서 확인 해보자.
large runners와 기본 runner의 성능차이
GitHub actions에 실행되는 processor 테스트 결과
•
총 10회 반복 테스트 해본 결과 아래 표와 같다.
기본 runner (2 코어)
CPU 명 | 싱글 | 멀티코어 | GeekBench | 추가 설명 |
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz | 1284 | 2775 | ||
Intel(R) Xeon(R) Platinum 8370C CPU @ 2.80GHz | 1229 | 2609 | ||
Intel(R) Xeon(R) Platinum 8171M CPU @ 2.60GHz | 689 | 1008 | - Geekbench 5 → Geekbench 6가 점수가 대체적으로 조금더 높게나오니 끽해야 (800, 900)
- CPU 사양은 2.60 Ghz이나 실제 성능은 2.09Ghz | |
Intel(R) Xeon(R) CPU E5-2673 v4 @ 2.30GHz | 924 | N/A | - Geekbench에 정확히 매칭되는 데이터로 존재하지 않음 |
•
기본 runner의 경우 여러 종류의 프로세서가 실행되는게 확인됐다.
4 코어 runner
CPU 명 | 싱글 | 멀티코어 | GeekBench | 추가 설명 |
AMD EPYC 7763 64-Core Processor | 1493 | 5922 |
•
4 코어 runner의 경우 AMD EPYC 7763 64-Core Processor로만 실행되는걸 확인했다.
•
기본 runner와 비교했을때 10% 정도 싱글코어 성능 향상이 존재하며, 멀티코어 성능은 당연하게도 2배정도 높았다.
•
성능향상은 테스트 속도 향상에 당연히 도움되지만 집중할 부분은 테스트의 신뢰성 향상이다. 원래 성공해야하는 테스트가 느린 속도로 인해 실패할 확률이 줄어든다는 뜻이다.
large runners의 단점
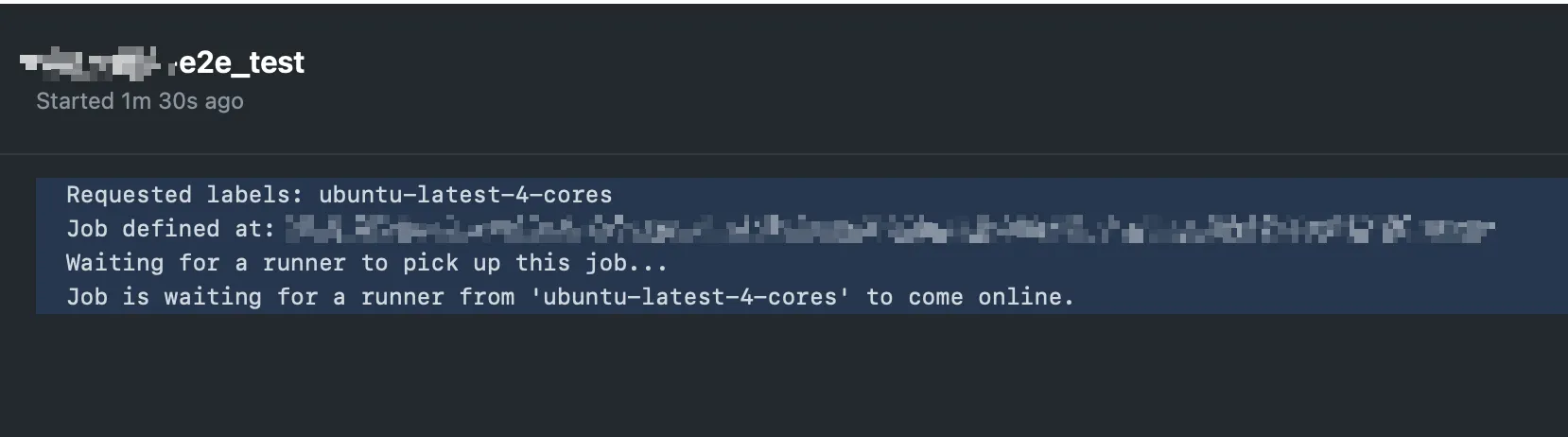
1분 30초 동안 할당받지 못한 large runner의 예시
•
이 글을 작성한 2023년 9월 기준으로 커스텀으로 설정한 large runner는 기본 runner 보다 해당 job에 runner를 할당 받는데 시간이 오래 걸린다. 위 사진은 1분 30초 동안 job이 runner를 할당받지 못한 경우에 해당된다. (결과적으로 해당 job은 runner를 할당 받기 까지 1분 42초가 걸렸다)
•
실제 job이 실행되는 시간에 1분 30초가 추가된다는 것 이다. 아무리 2배의 요금을 쓰며 larger runner를 사용하여 실행 시간을 20초 줄인다 하더라도 1분 30초가 추가되면 결과적으로는 1분 10초가 더 걸리는 CI가 되는 것 이다.
7. Flaky한 테스트코드
결과가 일관적이지 않고 예측불가능한, 신뢰할 수 없는 테스트 코드를 뜻한다.

flaky 사전 검색 결과
•
Flaky라는 단어는 “신뢰할 수 없는”이라고 해석된다. Playwright가 CI 환경에서 왜 Flaky 한걸까?
•
간단하게 설명하자면 unit, component 테스트와는 다르게 E2E 테스트는 실제 브라우저 환경에서 테스트하므로 환경(테스트 수행 머신의 성능과 같은)에 많은 영향을 받기 때문이다.
•
당신의 E2E 테스트케이스 중 하나가 통과됐다 안됐다 한다? → 축 당첨! 글을 읽고 있는 당신의 테스트코드는 falky한 코드이다.
나만 Flaky해?
Are your Playwright tests flaky when run in github actions? · microsoft/playwright · Discussion #22160
Hi, we are running Playwright tests in github actions (self hosted runners) and, what seems to be at random occasions, our app is not loading or loads super slowly to the point that Playwright test...

https://github.com/microsoft/playwright/discussions/22160
flaky playwright test - Playwright GitHub discussion
•
당신의 테스트 코드만 flaky 한게 아니다, 모두의 테스트가 CI 환경(을 포함한 로컬 개발환경)에서 flaky 하다.
e2e 테스트는 무겁다
•
기본적으로 e2e 테스트는 무겁다는 사실, 그리고 GitHub actions의 기본 runner는 낮은 퍼포먼스를 가지고 있다는 사실은 이전 포스트에서 확인했다. 이 두 사실의 조합으로 하나의 문제점이 발생하는데 바로 CI 환경 e2e 테스트의 높은 실패율이다.
•
처음 테스트 코드를 작성하고 로컬 머신(필자의 경우 m2 pro with 32GB RAM)에서는 문제없이 실행되는 테스트 코드를 GitHub actions 기본 runner 환경에서는 실패하는 경우를 쉽지않게 볼 수 있을 것이다.
•
unit, component 테스트의 경우 복잡성이 낮고 환경에 대한 영향을 많이 타지않아 테스트 속도가 느려지는 경우외에 이런 현상이 거의 발생하지 않는다.
•
하지만 unit, component 테스트와 다르게 e2e 테스트의 경우 실제 headless 브라우저에서 테스트 하기 때문에 더욱더 성능으로 인한 문제점이 많이 발생한다. 결과적으로 “개발자가 유도한 상황”이 연출되는게 아니라 전혀 다른 상황이 연출되기도 한다.
◦
Hydration 시간이 느려져 test worker가 DOM 요소에 접근시간이 오래 걸려 테스트 실패
◦
몇몇 스크롤, 클릭, 타이핑의 행위가 너무빨리 실행되어 브라우저에서 받아들이지 못해 개발자가 유도한 상황이 출력되지 않아서 실패
◦
캔버스에 객체를 그리려 했으나 느린 환경에서 state 변화에 대한 화면 렌더링이 오래걸려 캔버스에 실제 페인팅 불가하여 실패
•
일관적인 CI에서 수행되는 e2e 테스트는 DX를 떨어 뜨리는데 가장 큰 역할을 했다. 분명히 로컬 머신에서는 문제없이 정상적으로 수행되어 PR open했는데 왜 CI 환경에서는 실패하고 실패한 테스트 코드에서 타이핑 속도를 늦추거나 waitForTimeout과 같은 메서드를 이용하여 명시적인 기다림 함수를 실행 할 수 밖에 없다.(Discouraged 임에도 불구하고)
DISCOURAGED된 waitForTimeout
7. 결론 - 적절한 선택
“우리(개발자)는 회사에 최선이 되는 선택을 할 의무가 있다”
•
오글거리는 말이지만 당연한 소리다. “회사돈이니까 뭐.. 걍 비싸고 빠른거 써”라며 전부다 최대 사양으로 선택하는 무책임한 행동은 직업 윤리에 맞지 않는 행동, 태도다. 과금 개선에 대한 최소한의 시도는 필수다.
◦
“지금 너무바쁘니까 일단 해놓고 나중에 개선해야지”라는 자세로 미룰 경우 정확한 듀데이트를 설정해야 한다. 요금 관련해서 누군가가 “이거 왜이리 많이 나와?”라고 할때까지 그 누구도 손대지 않을 확률이 매우 높다.
•
large runners 항목에서 확인했듯이 두배의 코어는 두배의 가격이된다. 하지만 모두가 알다시피 코어수와 걸리는 시간은 비례하지 않는다. → 네트워크를 이용해 다운받는 작업들, job setting 더 나가서 job을 실행할 runner를 할당받기위해 대기하는 시간에는 퍼포먼스의 영향을 상대적으로 덜 받기 때문이다.
◦
??? : “개발자 2명 됐으니까 개발시간은 반으로 줄어드는거 맞지?”
변수
•
large runner가 job에 할당 되기까지 걸리는 시간
◦
위에서 언급했듯이 large runner가 job에 할당 되기까지 1분이상 걸리는 경우가 있다. 이 변수까지 더하는 경우 기본적으로 matrix와 sharding을 이용한 기본 runner로 수행하는 테스트가 더 빠르다.
•
large runner의 코어당 성능 증가
◦
large runners는 코어의 수만 늘어나는게 아니라 코어당 성능도 소폭 증가한다. 코어 수의 증가도 속도 개선에 유의미한 결과를 가져오지만 느린 성능으로 인한 테스트 깨짐 현상이 발생할 확률도 감소한다. → 테스트의 일관성, 신뢰성 증가.
벤치마크 표 작성하기
job 개수 | 코어 수 | playwright worker 수 | 소요시간 | 부가되는 요금(초) |
1 job | 2 코어 | 1 worker | 6분 30초 | 390초 |
3 jobs | 2 코어 | 1 worker * 3 jobs | 최대 3분 6초 | 대략 382초 |
1 job | 8 코어 | 1 worker | 3분 50초 | 920초 |
1 job | 8 코어 | 2 worker | 2분 43초 | 652초 |
1 job | 8 코어 | 4 worker | 2분 16초 | 544초 |
1 job | 4 코어 | 1 worker | 4분 28초 | 536초 |
1 job | 4 코어 | 2 worker | 3분 14초 | 388초 |
1 job | 4코어 | 3 worker | 2분 55초 | 350초 |
2 jobs | 4코어 | 2 workers * 2 jobs | 최대 2분 25초 | 580초 |
•
각 코어수가 증가(runner의 성능 증가) 할수록 당연하게도 시간은 줄어드나 Playwright의 worker 그리고 sharding이라는 변수가 존재한다. 서비스마다, 팀마다 테스트 코드의 기준, 테스팅 라이브러리, 복잡도가 전부 다르기 때문에 runner와 worker, sharding을 조합하여 최적의 값을 추론할 수 있는 설정할 표를 직접 만들어 계산 및 비교해야한다.
◦
코어 이상의 playwright worker를 설정할 경우 그보다 낮은 worker보다 시간이 더 걸리는 경우가 더 많아 해당 케이스는 표에 추가하지 않았다.
•
위와 같은 표를 작성하고 자신이 혹한 팀원들과의 회의를 거쳐 최선의 정책을 선택해보자.
7.1 - 나의 결론, BuildJet
CPU 명 | 싱글 | 멀티코어 | GeekBench | 추가 설명 |
AMD Ryzen 9 5950X 16-Core Processor | 2167 | N/A | ||
AMD Ryzen 9 7950X3D 16-Core Processor | 2907 | N/A | 8코어 선택 시에만 확률적으로 사용됨 |
•
싱글코어 성능만 보더라도 압도적이다. Github actions large runners 옵션을 선택하더라도 싱글코어 퍼포먼스가 최고 1400정도이지만 Buildjet의 runner들은 기본 2100점 대 부터 시작한다. → 위에도 몇번 말했지만 싱글코어 성능의 향상은 테스트의 속도 증가 뿐 아니라 테스트의 일관성 보장까지 해준다. 아! 완벽해!
◦
설정마저 너무 쉽다! 5분 내에 설정이 가능하다.
•
더 빠른 성능 + 빠른 Job 할당 + 결과적으로 별로 차이나지 않는 가격의 이유로 본인은 BuildJet으로 최종 설정을 변경했다.
같은 요금 다른 성능
BuildJet runner 사용 시

GitHub actions 기본 runner 사용 시
•
같은 요금을 사용한 runner 사용 시 성능 차이다. → e2e 테스트의 시간이 최소 1분씩 줄어든걸 확인할 수 있다.
◦
BuildJet - 4 cores
◦
GitHub actions- 2 cores
•
BuildJet이 1분정도 더 빠르게 테스트가 완료되며 결과또한 Flaky 하지않은, 더 stable한 결과다.
GitHub actions와 요금 비교
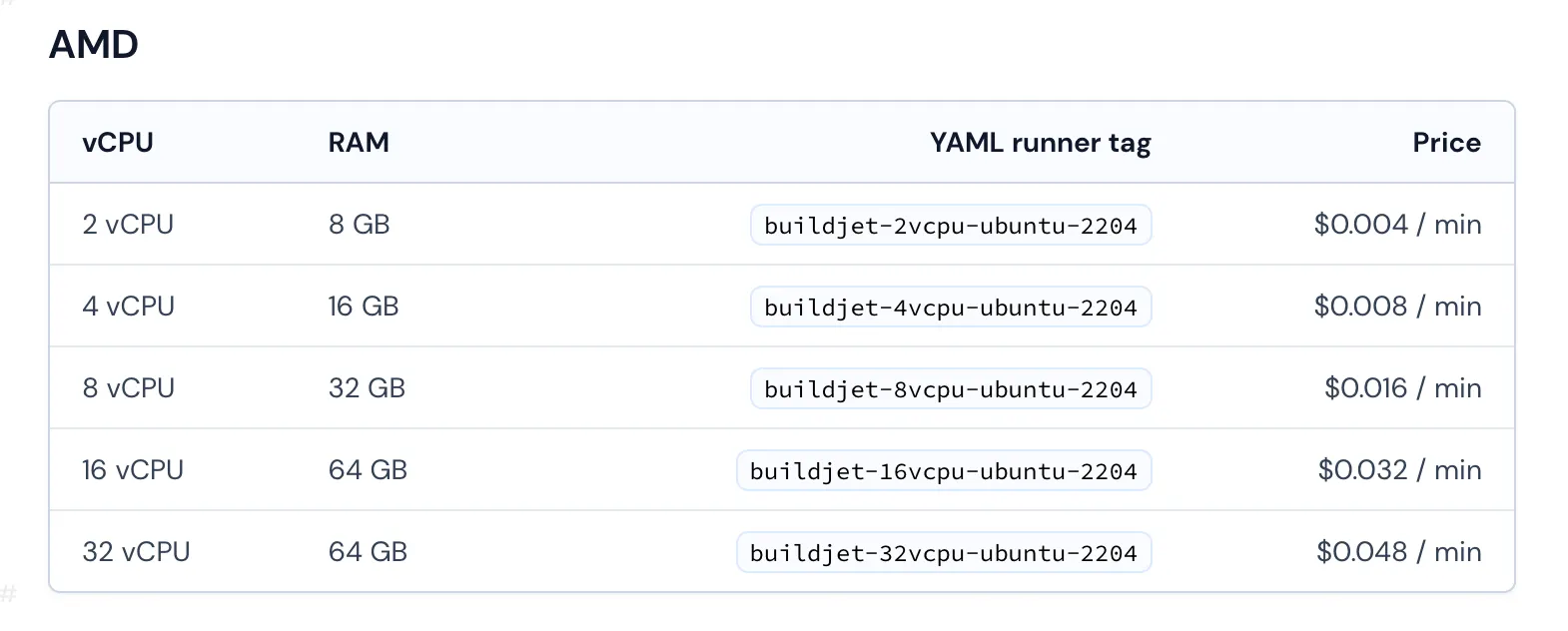
BuildJet 요금제

GitHub actions 요금제
•
BuildJet의 CPU 코어 당 가격은 GitHub actions의 코어당 가격과 비교했을때 2분에 1이다. → “BuildJet 4 cores를 GitHub actions 기본 runner(2 cores)가격으로 이용할 수 있다.”
•
표면적인 코어당 가격, 그리고 성능만 본다면 잘 “BuildJet이 싸고 더 좋은 데 굳이. GitHub actions를 쓸이유가 있어?” 라는 생각이 들 수 있지만 결론부터 말하자면 아니다. → 장단점이 분명히 존재하는 서비스다.
GitHub runner vs BuildJet runner
GitHub | Build Jet | |
무료사용시간 | 3000분 | X |
Large runner시 Job 할당 시간(BuildJet의 경우 모든 runner) | 평균적으로 1분 30초 | 평균적으로 10초이내 |
코어당 성능 | | |
Linux 외 타 OS 지원 (Windows, mac OS) | | |
•
무료사용시간 → GitHub runner의 경우 3000분의 무료시간이 존재하지만 BuildJet의 경우 무료사용시간은 존재하지 않는다.
◦
하지만 이 GitHub의 무료 사용 시간은 large runner 사용 시 해당되지 않는다.

공식 문서에 존재하는 무료사용시간 사용 불가
◦
위에서 확인할 수 있듯이 결과적으로 테스트에 사용되는 시간이 많이 줄기 때문에 이 무료사용시간에 의한 가격의 차이 또한 다소 줄어든다.
•
Large runner 시 Job 할당시간 → GitHub의 경우 Large runner 사용 시 매번 Job에 runner를 할당받는데 일정 시간이 소요됐다. 길게는 1분 30초까지 걸렸다. 반면에 BuildJet은 평균적으로 10초 이내에 Job에 runner를 할당 받았다.
•
코어당 성능 → 최대 40퍼센트정도 차이가 난다.
•
Linux외 타 OS 지원 (Windows, mac OS) → GitHub은 쉽게 사용할 수 있으나, BuildJet의 경우 달 단위로 10개 이상의 runner만 대여할 수 있다. 지원 하지만 사실상 표면적인 지원으로만 생각하면 편하다.

BuildJet의 mac OS M1 runners, Windows Runners 제한 사항
결론
•
mac OS와 Windows runner가 필요하다 → GitHub actions
•
코어당 성능이 중요한 작업이 아니다 → GitHub actions
◦
위와 같은 케이스에 해당되지 않는다면 BuidJet 사용을 고려해보자.
7-2. 높은 요금에 대한 태클
Experiment: The hidden costs of waiting on slow build times
How much does it really cost to buy more powerful cloud compute resources for development work? A lot less than you think.

https://github.blog/2022-12-08-experiment-the-hidden-costs-of-waiting-on-slow-build-times/

느린 빌드를 기다리는 시간으로 인한 비용에 대한 Github Blog 글
•
Github에서 작성한 느린 빌드를 기다리는 시간의 비용에 대한 블로그 글이다. 누군가(절대 C레벨 아닙니닷)가 “이거 요금 너무 비싼거아냐?”라고 태클걸었을때 해당 링크를 전달해주자. 우리 모두가 행복해 지지 않을까?
•
결과적으로 해당 아티클에서 하는 말은 "개발자 시간아끼는 비용이 요금이 비싼 액션 사용하는거 보다 싸게 먹힌다” 이다.